
A while ago I wrote some code at work that computed some signal processing stuff on an incoming stream of data. It looked likes this (in python):
class StreamComputation:
def __init__(self):
# Initialize value to 0.
self.x = 0
def nextValue(self, incoming):
# Add incoming and return.
self.x += incoming
return self.x
After some time had passed, I got the requirement to add a stage to the computation that would run before the code I had already written, and change a little bit the written code. With a bit of time pressure, I quickly added a function for the new first stage, added a variable, and an if to branch between the stages. It looked something like this:
class TwoStagedStreamComputation:
def __init__(self):
# Initialize stage to 1.
self.stage = 1
# Initialize value to 0.
self.x = 0
def stage1(self, incoming):
self.x += incoming
if self.x >= 10:
self.stage = 2
return self.x
def stage2(self, incoming):
# Add (some computation on) incoming and return.
self.x += someComputation(incoming)
return self.x
def nextValue(self, incoming):
if self.stage == 1:
return self.stage1(incoming)
else:
return self.stage2(incoming)
Tests were updated, QA had a check, maybe there was a code review (maybe not), and the code shipped. There was *no* bug in the code. But I still feel that I didn’t do it right.
Beyond this one example, all over our code base at work, and in some of my private projects, I have similar looking code. Sometimes I have a member or two expressing the stage of computation a class is in, and sometimes it’s about stage of data entry in GUI. Actually quite a bit of old GUI code I have is written like this (not all, see my post on using generators for GUI).
After some more time had passed, and after watching all kinds of YouTube videos on programming, I stumbled on State Machines. Sure, I am familiar with the concept. I even have quite a bit of code that names itself “Sate Machine”. But it’s not really a state machine, and it’s not the best code.
One of the videos was about a particular generic state machine implementation for C++. So at this point I realized that probably all languages have many implementations of state machines. And this is great. I’m still researching some libraries, but I’m definitely going to pick one for each language I program in (mostly python and C++). But during this research period I also found Peter Norvig’s presentation Design Patterns in Dynamic Programming, in which he basically says that the Sate Pattern isn’t needed in dynamic languages!
The state pattern is not exactly the same as a state machine. I didn’t know what the state pattern was until I saw Peter Norvig’s presentation, but once I learned about it I realized how to utilize the pattern, in a dynamic language, and to make my code slightly better:
class FPtrTwoStagedStreamComputation:
def __init__(self):
# Initialize nextValue to first function.
self.nextValue = self.nextValueStage1
# Initialize value to 0.
self.x = 0
def nextValueStage1(self, incoming):
self.x += incoming
if self.x >= 10:
self.nextValue = self.nextValueStage2
return self.x
def nextValueStage2(self, incoming):
# Add (some computation on) incoming and return.
self.x += someComputation(incoming)
return self.x
The change is that I keep a “function pointer” to the current computation stage, and change it when I transition. This removes the if condition on stages. I think this is basically the state pattern, modified for a dynamic language where functions are first class, in the way Norvig meant. I like it!
But how do I know that this reduces the complexity of my code? I actually asked myself this. Then google. And google came through. Google found some StackOverflow answer on reducing branch conditions that contained the term Cyclomatic Complexity. Alright! This is basically a quantitative measurement of how complicated a program is, which counts the number of linearly independent paths in the program. Really it’s about the number of branchings (if/switch/for/while/try…) the program has.
This is a completely new term for me, and I can already see myself overusing it all the time. But let’s stick to the code at hand. So in the first `TwoStagedStreamComputation` class, with the if statement, the cyclomatic complexity of the functions are as follows:
1. stage1 – 2
2. stage2 – 1
3. nextValue – 2
In the `FPtrTwoStagedStreamComputation` class, with the function pointer and no if statement, the cyclomatic complexity of each function is:
1. nextValueStage1 – 2
2. nextValueStage2 – 1
And that’s it! So there’s 2 whole cyclomatic complexity points less. The code is definitely better! Ahahahahahahahhahaha
Anyway… At this point I am pretty sure that the state pattern (or state machines, for different purposes) is useful and reduces the complexity of code. I’ll finish the post with thoughts on what to do when there’s more than one function to each stage of computation.
Say that there’s another function that we must expose, called `reset`, which behaves differently between the stages. In the first stage, calling `reset` returns `self.x` to 0, and in the second stage to `10`. One way to add this to the code is simply with another function pointer:
class FPtrTwoStagedStreamComputationAndReset:
def __init__(self):
# Initialize nextValue to first function.
self.nextValue = self.nextValueStage1
self.reset = self.reset1
# Initialize value to 0.
self.x = 0
def nextValueStage1(self, incoming):
self.x += incoming
if self.x >= 10:
self.nextValue = self.nextValueStage2
self.reset = self.reset2
return self.x
def reset1(self):
self.x = 0
def nextValueStage2(self, incoming):
# Add (some computation on) incoming and return.
self.x += someComputation(incoming)
return self.x
def reset2(self):
self.x = 10
This may start to look not so maintainable. What if we need to add even another function later? Will we remember to set all the pointers? We can bunch up the functions pointers corresponding to each computation stage in a value. The usual way to bunch function pointers is using a class. In a dynamic language, this is basically what classes are: bunching of values, such as function pointers, since we’re in a dynamic language. So maybe something like this:
class ClassesTwoStagedStreamComputationAndReset:
def __init__(self):
# Initialize stage to first class.
self.stage = FPtrTwoStagedStreamComputationAndReset.stage1
# Initialize value to 0.
self.x = 0
def nextValue(self, incoming):
return self.stage.nextValue(self, incoming)
def reset(self):
self.stage.reset(self)
class stage1:
@staticmethod
def nextValue(self, incoming):
self.x += incoming
if self.x >= 10:
self.stage = FPtrTwoStagedStreamComputationAndReset.stage2
return self.x
@staticmethod
def reset(self):
self.x = 0
class stage2:
@staticmethod
def nextValue(self, incoming):
# Add (some computation on) incoming and return.
self.x += someComputation(incoming)
return self.x
@staticmethod
def reset(self):
self.x = 10
As to which code is more readable, maintainable, or just better, I currently have no personal opinion. The cyclomatic complexity, other than having 2 more functions in the second alternative (for `nextValue` and `reset`) which don’t really count, is the same. The second alternative now really looks like the state pattern, as defined in the Wikipedia article, so maybe there’s another, cleaner way to do it in a dynamic language. I’m going to ask around to see what other people think. What about you, what do you think?
An important note is that everything here can be done in languages with functions pointers, which include C++. In fact, in C++ we can use type erasure, like `std::variant` or `std::function` (storing a `std::bind` if needed) to point to the current stage structure (be it a state instance or a function).
Other than the state-machine-like code that I have that will undergo significant modification once I choose state machine libraries, I also have a lot of code that looks like a pipeline:
def algorithm(input1, input2):
do_stuff
if condition:
do_more_stuff
for something in some iterator:
if another condition:
for elements in another iterator:
if last condition:
return I found something!
There are no else’s, and no early breaks. The code only flows forward. So this isn’t a state machine or state pattern. It’s a pipeline. And it has high cyclomatic complexity. I hope to write a post on how to reduce the complexity of this kind of code.
 , given as
, given as  coefficients for a sample rate
coefficients for a sample rate  , and the frequency band of interest being
, and the frequency band of interest being ![[f_1, f_2]](https://s0.wp.com/latex.php?latex=%5Bf_1%2C+f_2%5D&bg=ffffff&fg=444444&s=0&c=20201002) , it is common to simply assume the sample rate is actually
, it is common to simply assume the sample rate is actually ![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p):=\frac{1}{n+1}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1}{N}(n+1)\le f \le \frac{f_2}{N}(n+1)}} w(\frac{f}{n+1})|\hat{p}(\frac{f}{n+1})|^2](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%29%3A%3D%5Cfrac%7B1%7D%7Bn%2B1%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1%7D%7BN%7D%28n%2B1%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2%7D%7BN%7D%28n%2B1%29%7D%7D+w%28%5Cfrac%7Bf%7D%7Bn%2B1%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7Bn%2B1%7D%29%7C%5E2&bg=ffffff&fg=444444&s=0&c=20201002)
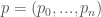 we put
we put  , and we have some coefficients
, and we have some coefficients  .
.![power_{[\frac{0}{N}, \frac{N/2}{N}]}^{approx}(p)=p_0^2+...+p_n^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7B0%7D%7BN%7D%2C+%5Cfrac%7BN%2F2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%29%3Dp_0%5E2%2B...%2Bp_n%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)

![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p)](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%29&bg=ffffff&fg=444444&s=0&c=20201002) we recognise that the numbers
we recognise that the numbers  are a subsequence of the discrete Fourier transform (DFT) of
are a subsequence of the discrete Fourier transform (DFT) of ![[\frac{f_1}{N}, \frac{f_2}{N}]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) . Instead of declaring the definition, I will first motivate it a bit. In the approximation above, we can double the sample rate we’ve assumed:
. Instead of declaring the definition, I will first motivate it a bit. In the approximation above, we can double the sample rate we’ve assumed:![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p;2):=\frac{1}{2n+2}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1}{N}(2n+2)\le f \le \frac{f_2}{N}(2n+2)}} w(\frac{f}{2n+2})|\hat{p}(\frac{f}{2n+2})|^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%3B2%29%3A%3D%5Cfrac%7B1%7D%7B2n%2B2%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1%7D%7BN%7D%282n%2B2%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2%7D%7BN%7D%282n%2B2%29%7D%7D+w%28%5Cfrac%7Bf%7D%7B2n%2B2%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7B2n%2B2%7D%29%7C%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)
 to get the sum:
to get the sum:![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p;M):=\frac{1}{M(n+1)}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1M}{N}(n+1)\le f \le \frac{f_2M}{N}(n+1)}} w(\frac{f}{M(n+1)})|\hat{p}(\frac{f}{M(n+1)})|^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%3BM%29%3A%3D%5Cfrac%7B1%7D%7BM%28n%2B1%29%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1M%7D%7BN%7D%28n%2B1%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2M%7D%7BN%7D%28n%2B1%29%7D%7D+w%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)
![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}(p):=\lim_{M\rightarrow\infty} \frac{1}{M(n+1)}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1M}{N}(n+1)\le f \le \frac{f_2M}{N}(n+1)}} w(\frac{f}{M(n+1)})|\hat{p}(\frac{f}{M(n+1)})|^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%28p%29%3A%3D%5Clim_%7BM%5Crightarrow%5Cinfty%7D+%5Cfrac%7B1%7D%7BM%28n%2B1%29%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1M%7D%7BN%7D%28n%2B1%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2M%7D%7BN%7D%28n%2B1%29%7D%7D+w%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)
![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}(p)=2\int_{\frac{f_1}{N}}^{\frac{f_2}{N}} |\hat{p}(f)|^2df.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%28p%29%3D2%5Cint_%7B%5Cfrac%7Bf_1%7D%7BN%7D%7D%5E%7B%5Cfrac%7Bf_2%7D%7BN%7D%7D+%7C%5Chat%7Bp%7D%28f%29%7C%5E2df.&bg=ffffff&fg=444444&s=0&c=20201002)
![f_1, f_2\in[0, \frac{1}{2}]](https://s0.wp.com/latex.php?latex=f_1%2C+f_2%5Cin%5B0%2C+%5Cfrac%7B1%7D%7B2%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) :
:
 . Putting the definition of
. Putting the definition of  into the definition of power we have:
into the definition of power we have:
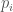 are real,
are real,  . We continue by setting:
. We continue by setting: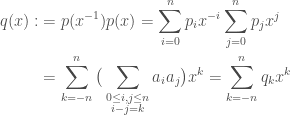

 . Also, set
. Also, set

 is the usual dot product. Note that the coefficients of
is the usual dot product. Note that the coefficients of 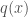 are also the coefficients of
are also the coefficients of  , which is a multiplication of two degree
, which is a multiplication of two degree  polynomials and hence can be computed using two FFTs. This shows that the power of a polynomial in a given band can be computed using two FFTs of size
polynomials and hence can be computed using two FFTs. This shows that the power of a polynomial in a given band can be computed using two FFTs of size 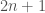 (number of coefficients of
(number of coefficients of  ), some exponentiating, and a dot product. Even though we took our sample rate to infinity, the computation turned out pretty simple.
), some exponentiating, and a dot product. Even though we took our sample rate to infinity, the computation turned out pretty simple.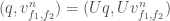
 is the unitary discrete Fourier transform operator. Since
is the unitary discrete Fourier transform operator. Since  can be expressed in terms of
can be expressed in terms of  :
:
 means component wise. If we already have
means component wise. If we already have  computed, this means that computing
computed, this means that computing  takes only a single FFT of size
takes only a single FFT of size 