** This post describes an idea that materialized after many many talks with Nathan and Hillel.
I’ve seen many deployment workflows and scripts, many of which use GitHub actions or equivalents, use Docker for build stages, and use terraform/cloudformation/scripts for deployment.
Once kinks are sorted out, these work really well.
The Infrastructure as Code movement is thriving, DevOps is better, and we’re happier.
Except, every time someone (usually me) pushes a weird enough merge commit on my github repo, the action to build and deploy my lambdas is triggered, the docker build is just a tiny bit different this time, and everything breaks.
Docker is not really reproducible
Unless you’re distroless and in control of everything (like Nathan is), you already know what I’m saying.
Usually it’s apt get that kills reproducibility, but it’s hardly the only danger.
Maybe always use the same machine?
One way to solve reproducibility is to always use the same machine on which you’ve done the docker builds that get deployed.
Docker will use cached layers on following builds, so the build artifacts will be the same.
But you want to use GitHub actions – so it’s always a new environment.
Replacing Reproducibility with Idempotency
I have come to terms with the fact that I cannot reproduce builds.
Not with the current technology stack I’m familiar with(*).
Instead, I’ll settle for not building a second time whatever I have already built, and not deploying a second time whatever I have already deployed.
The action of build and deploy needs to be idempotent.
Sometimes GitHub actions are presented as idempotent, in that you can set that only changes to parts of your code trigger a workflow.
But since the trigger is based on the commit tree – and not the code itself – the workflow can still trigger even if the code didn’t change.
Moreover, if a deployment is triggered for one artifact, usually this cascades into a build and deploy of all artifacts, even if the others didn’t change.
(*) There’s a package manager called Nix, and an OS called NixOS, that maybe completely solve reproducible idempotent builds and deployments, but I haven’t understood them yet.
The new recipe
I’ll present the solution I’ve started using, with the concrete choices I made, though there’s a clear general principle that can be extracted and translated into other environments.
1. Put build stages in a DVC DAG
What is DVC?
DVC is short for Data Version Control, and it is a python package for keeping track of data, machine learning experiments, and models.
Putting aside the original intent of DVC, it is perfect for idempotent builds:
- You define build stages
- Each stage spells out explicitly its dependencies – all the code it uses
- Each stage writes explicitly its outputs – built artifacts
- On rerunning, only changed stages are rerun – idempotency.
Note, though DVC is a python package, none of your code needs to be in python, and nothing in my recipe uses python. DVC is just a neat tool for pipeline and remote storage management.
Wait, why not make?
Yes, you can define DAGs of builds using make, and in fact this is very common.
But:
- Running
make a second time is idempotent only if you’re on the same machine, which you’re not, since you’re on GitHub actions. - The artifacts are not automatically stored anywhere.
What does DVC look like?
Here is a dvc.yaml file defining a single build stage:
stages:
myapp:
deps:
- myapp/
- buildmyapp.sh
cmd: ./buildmyapp.sh
outs:
- "artifacts/myapp.zip"
In DVC terminology, this is a pipeline with a single stage, that depends on everything in the myapp directory, and also on the script to build the app
The stage also declares a single output, a zip file that will go in the artifacts directory.
2. Define a DVC remote
Similar to a git remote, you tell DVC where you want data files pushed to.
Generalizing the original intent of the authors of DVC, instead of pushing raw data of some kind, or some machine learning model, we will push the built zip file that is our application.
Personally, I defined my remote to be on S3.
We’ll soon talk about when to actually push the artifacts to the remote.
3. Put the deployment as a stage
To make deployment contingent on the code actually changing, all we have to do is use the DAG we have, in this case dvc.yaml.
Updating the dvc.yaml pipeline file above, it looks like this:
stages:
myapp:
deps:
- myapp/
- buildmyapp.sh
cmd: ./buildmyapp.sh
outs:
- "artifacts/myapp.zip"
deploy:
deps:
- artifacts/
- deploy.sh
cmd: ./deploy.sh
The deploy stage depends on the artifacts directory, so any time it is modified by the first stage the deploy stage will also run.
But the deploy stage can also run if only the deploy script is changed.
This is where we already can see some idempotency: if we don’t change myapp’s code, the artifact won’t change, and so its deployment won’t be affected. Even if GitHub decided to run the workflow that runs DVC.
4. The GitHub Workflow
The GitHub workflow needs to run these commands:
dvc pull \
&& dvc repro \
&& dvc push \
&& git add dvc.lock \
&& git commit -m "updated dvc.lock" \
&& git push
Of course the environment in which commands run needs to have DVC installed, as well as credentials to push to the dvc and git remotes.
dvc pull
This pulls the previously built artifacts from the DVC remote, in my case from S3.
If we changed the deploy script, but not myapp, we still need the myapp zip artifact for the deploy script to work correctly.
Since we’re pulling exactly the zip file that was deployed last, we know for certain that we aren’t changing myapp.
dvc repro
This runs the stages in the pipeline defined in dvc.yaml.
dvc push
This pushes the created artifacts to the DVC remote.
The point here is that on following builds, even if they are on different machines, we’ll still get the last built artifact from dvc pull.
This combination of dvc push and dvc pull is one of the key differences from using make.
git add+commit+push
If any of our code changed, whether it’s the myapp code, the deployment script, or both, the hashes have changed.
Hashes of pipeline dependencies are stored in a file called dvc.lock.
We push the changes to origin.
Is it ok to push from a workflow action? Won’t we get an infinite loop?
This is where idempotency is critical.
The push of dvc.lock will indeed trigger another run of the workflow.
But this time, since the code hasn’t changed since the last run, all hashes will be the same, and DVC won’t run any of the pipeline stages.
This means there won’t be anything to git push, and we won’t get a third run of the workflow.
Versioning
Questions of identity go back thousands of years.
If we change one line of code, then another, and then another, until all code has been refactored, is it still the same code?
We’ll go with no.
Code is exactly the same only if it really is exactly the same.
Assuming our hash function has few collisions, we’ll also allow for the hash of code to identify it.
Given this, in order to know the version of a deployed artifact, we just need to know its hash.
Version in Logs
The most common type of versioning requirement is that the version be printed in logs of systems running the artifact.
In my own current projects the artifacts are zip files that are deployed to AWS lambda, and these zips contain python packages.
Here is the top of my lambda function:
def lambda_handler(event, context):
print(f"CODE_ZIP_HASH='{os.environ.get('CODE_ZIP_HASH', 'n/a')}'")
This prints (to cloudwatch) the environment variable CODE_ZIP_HASH.
I populate this variable through the definition of the lambda in the deployment script.
Specifically, my deployment script uses AWS CDK, also in python, and the relevant lines are these:
code_zip_hash = hashlib.md5(open(zip_path, 'rb').read()).hexdigest()
func = aws_lambda.Function(
stack,
"myapp",
runtime=aws_lambda.Runtime.PYTHON_3_8,
code=_lambda.Code.from_asset(zip_path),
handler='lambda_function.lambda_handler',
description="Best app ever!",
timeout=timeout,
environment={'CODE_ZIP_HASH': code_zip_hash}
)
There’s an additional layer of awesomeness here: DVC also uses md5 as its hashing algorithm.
Say the md5 hash of an artifact at some point was “b0d7…”, and we see it in some log.
Even if the repo has since moved on, we can look for all commits whose dvc.lock file has this hash “b0d7…”.
Though getting the commits is helpful, remember that builds aren’t reproducible, so if we want the actual artifact corresponding to “b0d7…” we need something else.
This is where DVC’s storage model comes in to play: it stores files exactly by their hash. In fact, it’s pretty much the same way git stores blobs.
So getting this old artifact is as simple as downloading /path/to/remote/b0/d7...
What about logging the commit itself?
Of course you can do it.
You can inject the current git commit into the artifact build stage.
Since git commits aren’t unique identifiers of artifacts, I chose not to do this in my own project.
Version in Deployment
Having the version printed in logs allows us to look back at what has already run.
But what if I want to know what will run if I trigger my lambda right now?
In my project, I wanted my lambda to have its unique identifier right in its description, so just by looking in AWS Console I can know what will run next.
All I had to do is update my lambda definition above to this:
code_zip_hash = hashlib.md5(open(zip_path, 'rb').read()).hexdigest()
func = aws_lambda.Function(
stack,
"myapp",
runtime=aws_lambda.Runtime.PYTHON_3_8,
code=_lambda.Code.from_asset(zip_path),
handler='lambda_function.lambda_handler',
description=f'Best app ever! [CODE_ZIP_HASH={code_zip_hash}]', # <-- modified line
timeout=timeout,
environment={'CODE_ZIP_HASH': code_zip_hash}
)
Recap
In order to have idempotent artifact builds and cloud deployments:
- Put builds and deployment as stages in a DVC pipeline.
- Define all the dependencies and outputs correctly.
- Use a DVC remote such as S3.
- Use:
dvc pull && dvc repro && dvc push && git add && git commit && git push. - It’s also easy to add identifiers and commit hashes to logs and descriptions.
The benefits are:
- Changing one artifact’s code does not force rebuilding other artifacts, even if you’re building on a new VM every time.
- Changing only the deployment script won’t build any artifacts at all.
- You have an artifact repository that just works.
- Your git history contains the hashes of all built artifacts.
- You can look up any artifact using its hash.
Alternatives
The usage of DVC in the recipe is pretty basic, and you could write the infrastructure yourself instead.
It’s mostly hashing things, saving to files, checking files, and hashing some more.
Nathan pointed me to git-annex, a tool that also saves files remotely in a git-like structure, referencing files by their hashes. You can replace that part of my recipe with git-annex.
There are also other pipeline tools out there, most familiar are AirFlow, Luigi, and Prefect.
These don’t understand caching, so I’m not sure how to replace DVC’s pipeline with theirs.
There is one more pipeline tool called Dagster, which has an experimental caching option. This can indeed replace DVC’s pipeline in the recipe.
Finally, Nix should get one more mention.
Nix is supposed to solve all reproducibility and idempotency problems by saving everything by hash. Really everything. From the libraries you use, to glibc itself. I’m still looking into this.


 – Rotations of a ball
– Rotations of a ball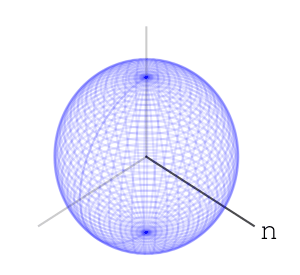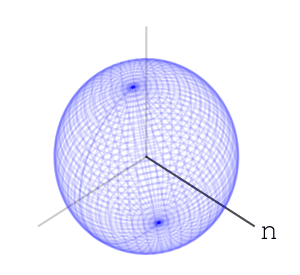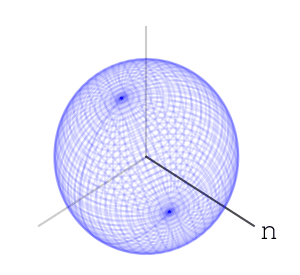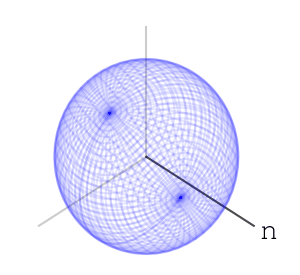

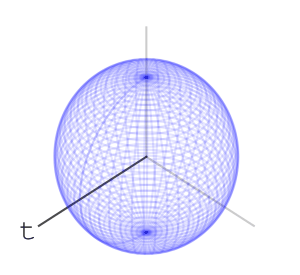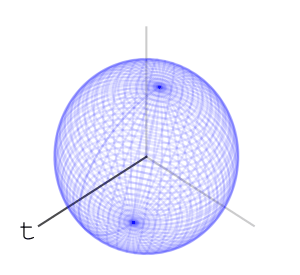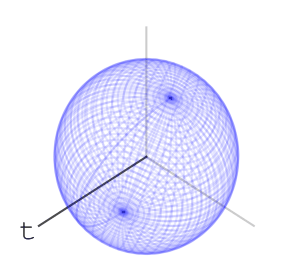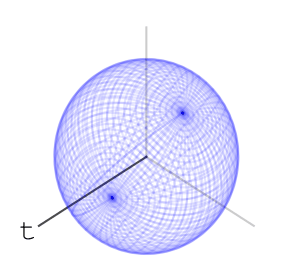
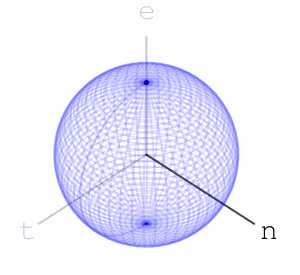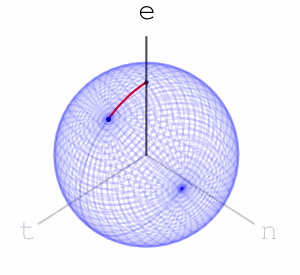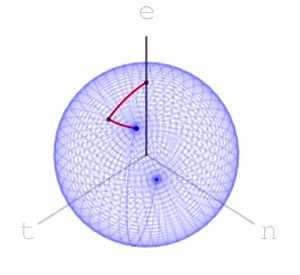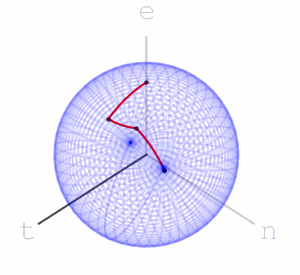

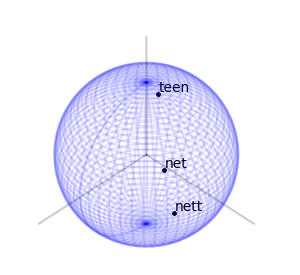
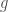 can move a point is the maximal eigenvalue of
can move a point is the maximal eigenvalue of  . If we choose all our elements of
. If we choose all our elements of  , for some small number
, for some small number 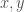 with Levenshtein distance
with Levenshtein distance  to a given fixed point can only result in a Euclidean distance not greater than
to a given fixed point can only result in a Euclidean distance not greater than  – each letter operation counts at most as changing two basic rotations.
– each letter operation counts at most as changing two basic rotations. end in a uniform-like distribution on the sphere. I can’t prove that this is indeed the case, and I’ve asked
end in a uniform-like distribution on the sphere. I can’t prove that this is indeed the case, and I’ve asked  – or any algebraic group. A nice property that the special orthogonal groups have is compactness. This means the numbers in our calculations can’t go crazy, and we should expect numerical stability. I also like that they’re connected. Another family of compact connected real algebraic groups is that of special unitary groups. Which is better practically is a question of performance of representation and multiplication of elements, and I don’t know the answer right now.
– or any algebraic group. A nice property that the special orthogonal groups have is compactness. This means the numbers in our calculations can’t go crazy, and we should expect numerical stability. I also like that they’re connected. Another family of compact connected real algebraic groups is that of special unitary groups. Which is better practically is a question of performance of representation and multiplication of elements, and I don’t know the answer right now. – Fixed length vectors
– Fixed length vectors in a connected compact real algebraic group
in a connected compact real algebraic group 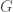 (such as
(such as  in a space on which
in a space on which 
 (each factor contributing 3 degrees of freedom).
(each factor contributing 3 degrees of freedom). , for a connected real compact algebraic group
, for a connected real compact algebraic group  are small. Enumerate the values of the pixels of each image as
are small. Enumerate the values of the pixels of each image as  (where we assume all images are gray-scale, though the following can also be done with more colors). We then have the following mapping:
(where we assume all images are gray-scale, though the following can also be done with more colors). We then have the following mapping:
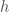 in the above formula as representing the passage of time. This mapping can, for example, be used to find pairs of stocks whose series of values are similar.
in the above formula as representing the passage of time. This mapping can, for example, be used to find pairs of stocks whose series of values are similar. and some random mapping from a given collection to
and some random mapping from a given collection to  , then we recover MinHash. Yey!
, then we recover MinHash. Yey! , one for each nucleobase, such that the embeddings of some sample of DNA sequences is relatively uniform on the sphere. We can create a loss function that measures the uniformness of these embeddings. This loss function is then a differentiable function in the coordinates of our four elements (given a choice of representation of
, one for each nucleobase, such that the embeddings of some sample of DNA sequences is relatively uniform on the sphere. We can create a loss function that measures the uniformness of these embeddings. This loss function is then a differentiable function in the coordinates of our four elements (given a choice of representation of 
 , what is the
, what is the  ?
?


 , given as
, given as  coefficients for a sample rate
coefficients for a sample rate  , and the frequency band of interest being
, and the frequency band of interest being ![[f_1, f_2]](https://s0.wp.com/latex.php?latex=%5Bf_1%2C+f_2%5D&bg=ffffff&fg=444444&s=0&c=20201002) , it is common to simply assume the sample rate is actually
, it is common to simply assume the sample rate is actually ![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p):=\frac{1}{n+1}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1}{N}(n+1)\le f \le \frac{f_2}{N}(n+1)}} w(\frac{f}{n+1})|\hat{p}(\frac{f}{n+1})|^2](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%29%3A%3D%5Cfrac%7B1%7D%7Bn%2B1%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1%7D%7BN%7D%28n%2B1%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2%7D%7BN%7D%28n%2B1%29%7D%7D+w%28%5Cfrac%7Bf%7D%7Bn%2B1%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7Bn%2B1%7D%29%7C%5E2&bg=ffffff&fg=444444&s=0&c=20201002)
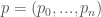 we put
we put  , and we have some coefficients
, and we have some coefficients  .
.![power_{[\frac{0}{N}, \frac{N/2}{N}]}^{approx}(p)=p_0^2+...+p_n^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7B0%7D%7BN%7D%2C+%5Cfrac%7BN%2F2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%29%3Dp_0%5E2%2B...%2Bp_n%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)

![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p)](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%29&bg=ffffff&fg=444444&s=0&c=20201002) we recognise that the numbers
we recognise that the numbers  are a subsequence of the discrete Fourier transform (DFT) of
are a subsequence of the discrete Fourier transform (DFT) of ![[\frac{f_1}{N}, \frac{f_2}{N}]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) . Instead of declaring the definition, I will first motivate it a bit. In the approximation above, we can double the sample rate we’ve assumed:
. Instead of declaring the definition, I will first motivate it a bit. In the approximation above, we can double the sample rate we’ve assumed:![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p;2):=\frac{1}{2n+2}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1}{N}(2n+2)\le f \le \frac{f_2}{N}(2n+2)}} w(\frac{f}{2n+2})|\hat{p}(\frac{f}{2n+2})|^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%3B2%29%3A%3D%5Cfrac%7B1%7D%7B2n%2B2%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1%7D%7BN%7D%282n%2B2%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2%7D%7BN%7D%282n%2B2%29%7D%7D+w%28%5Cfrac%7Bf%7D%7B2n%2B2%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7B2n%2B2%7D%29%7C%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)
 to get the sum:
to get the sum:![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}^{approx}(p;M):=\frac{1}{M(n+1)}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1M}{N}(n+1)\le f \le \frac{f_2M}{N}(n+1)}} w(\frac{f}{M(n+1)})|\hat{p}(\frac{f}{M(n+1)})|^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%5E%7Bapprox%7D%28p%3BM%29%3A%3D%5Cfrac%7B1%7D%7BM%28n%2B1%29%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1M%7D%7BN%7D%28n%2B1%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2M%7D%7BN%7D%28n%2B1%29%7D%7D+w%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)
![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}(p):=\lim_{M\rightarrow\infty} \frac{1}{M(n+1)}\sum_{\substack{f\in\mathbb{N} \\ \frac{f_1M}{N}(n+1)\le f \le \frac{f_2M}{N}(n+1)}} w(\frac{f}{M(n+1)})|\hat{p}(\frac{f}{M(n+1)})|^2.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%28p%29%3A%3D%5Clim_%7BM%5Crightarrow%5Cinfty%7D+%5Cfrac%7B1%7D%7BM%28n%2B1%29%7D%5Csum_%7B%5Csubstack%7Bf%5Cin%5Cmathbb%7BN%7D+%5C%5C+%5Cfrac%7Bf_1M%7D%7BN%7D%28n%2B1%29%5Cle+f+%5Cle+%5Cfrac%7Bf_2M%7D%7BN%7D%28n%2B1%29%7D%7D+w%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5Chat%7Bp%7D%28%5Cfrac%7Bf%7D%7BM%28n%2B1%29%7D%29%7C%5E2.&bg=ffffff&fg=444444&s=0&c=20201002)
![power_{[\frac{f_1}{N}, \frac{f_2}{N}]}(p)=2\int_{\frac{f_1}{N}}^{\frac{f_2}{N}} |\hat{p}(f)|^2df.](https://s0.wp.com/latex.php?latex=power_%7B%5B%5Cfrac%7Bf_1%7D%7BN%7D%2C+%5Cfrac%7Bf_2%7D%7BN%7D%5D%7D%28p%29%3D2%5Cint_%7B%5Cfrac%7Bf_1%7D%7BN%7D%7D%5E%7B%5Cfrac%7Bf_2%7D%7BN%7D%7D+%7C%5Chat%7Bp%7D%28f%29%7C%5E2df.&bg=ffffff&fg=444444&s=0&c=20201002)
![f_1, f_2\in[0, \frac{1}{2}]](https://s0.wp.com/latex.php?latex=f_1%2C+f_2%5Cin%5B0%2C+%5Cfrac%7B1%7D%7B2%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) :
:
 . Putting the definition of
. Putting the definition of  into the definition of power we have:
into the definition of power we have:
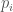 are real,
are real,  . We continue by setting:
. We continue by setting: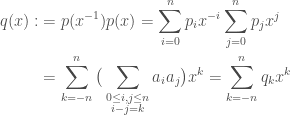

 . Also, set
. Also, set

 is the usual dot product. Note that the coefficients of
is the usual dot product. Note that the coefficients of 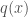 are also the coefficients of
are also the coefficients of  , which is a multiplication of two degree
, which is a multiplication of two degree 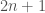 (number of coefficients of
(number of coefficients of  ), some exponentiating, and a dot product. Even though we took our sample rate to infinity, the computation turned out pretty simple.
), some exponentiating, and a dot product. Even though we took our sample rate to infinity, the computation turned out pretty simple.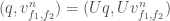
 is the unitary discrete Fourier transform operator. Since
is the unitary discrete Fourier transform operator. Since  can be expressed in terms of
can be expressed in terms of  :
:
 means component wise. If we already have
means component wise. If we already have  computed, this means that computing
computed, this means that computing  takes only a single FFT of size
takes only a single FFT of size 



